キカガクの機械学習動画に待望の中級編が追加されました。初級編が好評だったみたいで、今回満を持して中級編が登場。初級編はとてもわかり易かったですよね。なので今回の中級編の登場には納得です。(上級編も期待してます!←気が早いか。^^; でも、講座の説明を見ると上級編も登場する雰囲気ですね。楽しみに待ちましょう。)
▶【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 中級編 –
![]()
公開後、すでに100人以上の方が受講されていますね。人気です。講師は初級編と同様、吉崎亮介さん。株式会社キカガクの代表取締役社長です。
ということで、早速ですが私もこの流れに乗っかってUdemyでポチッと購入して視聴してみました。今回の記事ではこの中級編動画の感想を書いてみたいと思います。中級編のゴールは「現場の解析」を知るです。
(参考1)初級編の感想はこちら↓

(参考2)初級編受講者の評価はこちら↓
受講者のレビューコメントも見れます。良い評価、普通の評価、まずまずの評価それぞれ確認できます。購入の参考にしてくださいね。
感想:【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 中級編 –
機械学習を学びたい人の多くは、ただ学ぶだけでは無く、程度の差はあれ仕事と絡めて機械学習を役立てたいという場合がほとんどでしょう。つまり、入門レベルからは早めに脱出して中級レベルを目指す必要があります。
また、機械学習などの最新技術は、知見がある人材は少ないことから、知らない人に向けてわかりやすく説明しなければならない場面も多いです。このキカガクの動画は一般的な動画解説とは少し違って、紙にペンで書きながら解説するスタイルとなっています。(全部がそうではないですが。)

この紙に書いて説明するというのが非常にわかりやすいのです。このようにキカガクのUdemy動画では、単純に機械学習に学べるだけではなく「機械学習をわかりやすく伝える技術」も学べるので、結構オイシイ動画となっています。実際の仕事でも真似できそうなヒントがたくさんあります。お客さんに話す場面でも使えるかも。
中級編ではどんなことが学べるのか?
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 中級編 -の講座内容です。↓
中級編では機械学習で必要な数学のエッセンスがたくさん詰まっている「重回帰分析」をゴールに、線形代数、統計、重回帰分析まで一気通貫で解説します。
すでにUdemyで公開されている初級編の知識を前提として始め、数学やPythonの実装も順を追って解説しますので、初めての方でも学べる内容となっています。
受講対象者
以下のような方を対象に制作された動画です。
- 機械学習の参考書を読んで「閉じて」しまった方
- 独学で機械学習を学ぼうと思ったけど挫折してしまった方
- 機械学習の参考書に記載された数式の意味が理解できず、学習をやめてしまった方
- 中学校で学ぶ数学から始めるので初心者の方、数学が苦手な方でも大丈夫
中級編はこんな講義
中級編には数学的な部分から、Pythonでの実装まで含まれています。講義の流れは以下のように進みます。
- 線形代数
- 重回帰分析
- 重回帰分析の実装
- 実データで演習
- 統計
- 外れ値除去/スケーリングを考慮した重回帰分析
- ビジネス活用
最後まで見ましたが、実際は中級の一歩手前のような印象。でも大事なエッセンスが詰まっています。これから学習をひとりで自走できるようになるために押さえておいたほうが良いポイントが盛り沢山です。
機械学習を学べる動画やサービスは増えてきましたが、数学の基礎の解説を盛り込んだ教材は少ない印象です。(※書籍ではここ半年くらいで増えてきています。)このキカガクの動画はうまくまとまっていました。
今後は(つまりこの先の上級編では)どういうシーンでどういうアルゴリズムを選んでいくべきかといった方向の話も聞きたいな〜と思いました。ハイパーパラメーターのチューニングなども。モデルを磨き込んでいく勘所なども聞いてみたいですね。ついでにリクエストすると、色々なシチュエーションでの前処理も見てみたいかも。上級編はこれから作っていくみたいです。
追記:
上級編ではハイパーパラメーターのチューニングについては扱うみたいですね。動画の最後の方で言及がありました。
▶【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 中級編 –
![]()
おまけ:受講時のメモ(感想)
以下はおまけ。受講時に取ったただのメモです。この動画の雰囲気が伝わるかもと思ったのでついでにアップしておきます。「こんな流れで進んでいくんだー」という参考に。というか、公式サイトのカリキュラムの目次を見れば流れはつかめるんですけどね^^; まずはそっちを見たほうがいいかも。
まずは線形代数の基礎から始まります。
-
スカラー・ベクトル・行列についての解説。この3つの違いが言えますか?数学に馴染みがない人向けに用語から解説してくれます。
-
あと、転置(行列)についての説明もあります。行と列を入れ替えることですね。転置って聞いてアレルギー起こす人はこのレクチャーは見ておきましょう。単純に入れ替えるだけですから。
-
行列の足し算・引き算の説明。掛け算(行列積)も。例として2×2の行列同士の掛け算を紙に書いて説明。高校の授業みたいで懐かしい気持ちになります。
-
行列の演算についての練習問題。ひとつひとつ解説。高校の数学の問題を先生が黒板で解いてくれるのを見ている感覚になります。(今回の動画では紙ですが。)
-
先生オリジナルの教え方「サイズ感」。先生が大事と思ったので説明に入れてくれたみたい。慣れない内はスクリーンショットとって持って多いてもいいかも。
-
転置についてもう少し詳しく。縦と横をひっくり返します。公式の説明も。転置は確か大学の最初で扱ってたかな。高校では習わない…はず?
-
単位行列。重回帰分析でもよく使う。定義だけでなくなんでこれが必要なのかも教えてくれます。
-
次は逆行列。インバースと言ったりとしますね。Aの逆行列を、Aのインバースと言ったり。
-
ベクトルで微分。偏微分を使います。偏微分についてはキカガクの初級編動画で解説してました。
-
大事な公式。ベクトルでの部分の公式を解説。よく使うので覚えておかないと。オンラインで拾える便利なPDFの紹介もあり。
ここまでで線形代数の基礎は終了。
これからは重回帰分析について。
-
まずは、重回帰分析とはなんだったけ?という説明。入力変数、予測値、重み、バイアスなどおさらいも。
-
線形代数(ベクトルの演算)を活用することで非常にすっきりと数式で表現することが出来ます。ここの表記で転置も使います。
-
次は評価関数。初級編で扱った単回帰分析と全く同じ評価関数を使います。二乗誤差の総和をとります。ベクトルの掛け算で表す方法の解説も。
-
評価関数を最小化するにはどうするか?という解説。最適なパラメータを求めていきます。ちょっと長めの式展開をしながら説明。この辺が理解できれば色々な機械学習の書籍が読みやすくなるかもです。
-
よくある質問についてのアンサーも。先程の行列の式変形に関する疑問。逆行列の条件は忘れないようにしたいですね。ポイントは「正方行列」です。
次は、重回帰分析をプログラミングで実装していきます。
-
まずは環境構築。Windows、Macどちらでも大丈夫です。(環境構築についてはキカガクのサイトを案内されます。)
-
みんな大好きJupyerNotobookを使いながらプログラミングをします。JupyterNotebookなので使用する言語はもちろんPythonです。
-
ベクトルや行列を扱うので、ライブラリのnumpyを使用。numpyのアレイにしてあげると計算ができるようになります。numpyを使わず、リストで計算しようとしてもうまくいかないのがわかると思います。なのでnumpyを使うというわけですね。
-
numpyの基本的な使い方の解説から。転置や逆行列も簡単に変換できます。
-
numpyでよくある間違いについての説明。間違えやすそうなポイントを教えてくれます。ちょっとしたことですがハマリポイントになり場合もあるので、あらかじめ注意するように教えてくれるのは優しいですね。オンラインのデジタルコンテンツだけれど、優しさが感じられます。
-
ついでにnumpyでよく使う処理についての説明もあり。
-
重回帰分析の実装の演習問題。まずはウォーミングアップ。
-
ここからは、numpyではなく、Scikit-learnでの実装を解説。実務ではなかなかnumpyで細かくコードを打っていくことは少ないですね。Scikit-learnを使うことで書くコードの量が大幅に減らせます。便利なライブラリです。
-
Scikit-learnのLinearRegressionを使って重回帰分析を行うデモ。さっきnumpyでやったことが秒速で出来てしまいます。
-
ここで新たなライブラリ登場。pandasです。データを効率的に扱えるため、この分野では欠かせないライブラリですね。まずはcsvデータの読み込みから。read_csv(‘xxx.csv’)ですね。
-
pandasでよく使う機能の紹介もあり。例えばdescribe()とか。
-
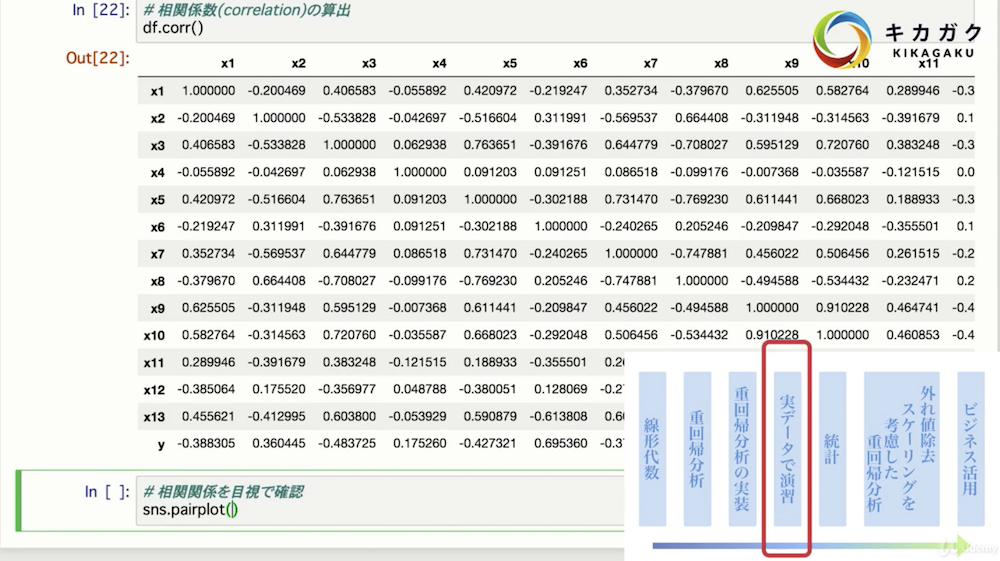
ここでまた新たなライブラリseabornも登場。matplotlibよりも表示がきれいですよね。(matplotlibの上に成り立っていたりました。)seabornでおかしなデータが含まれていないか確認していきます。
-
いきなり機械学習をするのではなく、まずはデータをながめることも大切ですね。相関係数なんかはすごく役立ちそうです。
-
seabornのpairplotも。機械学習の入門書籍でもよく紹介されているやつです。他のUdemyの人口知能系の入門動画でも紹介されていましたね。分析の出だしで間違った方向に突っ走らないためにpairplotを眺めることも重要。
-
pandasでcsvで読み込んだデータを入力変数と出力変数に分けます。機械学習はここからですよね。
-
次はモデルの構築と検証。さっき分けた入力変数と出力変数を使います。モデルを宣言→モデルの学習→検証という流れを確認していきます。numpyで細かく計算していくのではなく、Scikit-learnを使ってサクッと行います。
-
訓練データと学習データの話に突入。どうして訓練データと検証データを分けないといけないかという根本的な説明から。分けないとカンニングしたみたいになっちゃいますよね。^^;
-
訓練データと学習データの分割を実装してみます。Scikit-learnの中に便利な関数があります。分け方には色々ありますが今回は基本のtrain_test_sprit()を使用。
-
予測値の計算。これもScikit-learnで行います。予測値の計算はpredict()で。
-
そして学習したモデルの保存の解説。joblibですね。ついでにモデルの読み込みの確認も。
ここで、一旦実装については終わり。
次は統計の話になります。また紙に書く解説に戻ります。
-
主な統計量についての解説。データを議論する上で最低限知っておいた方が良いものを紹介。
-
平均、分散、母分散、標本分散、標準偏差の解説。よく耳にする標準偏差。あなたは説明できますか?データのばらつきを定量評価することができます。
-
基本的なことを学んだので確認のためここで練習問題。
-
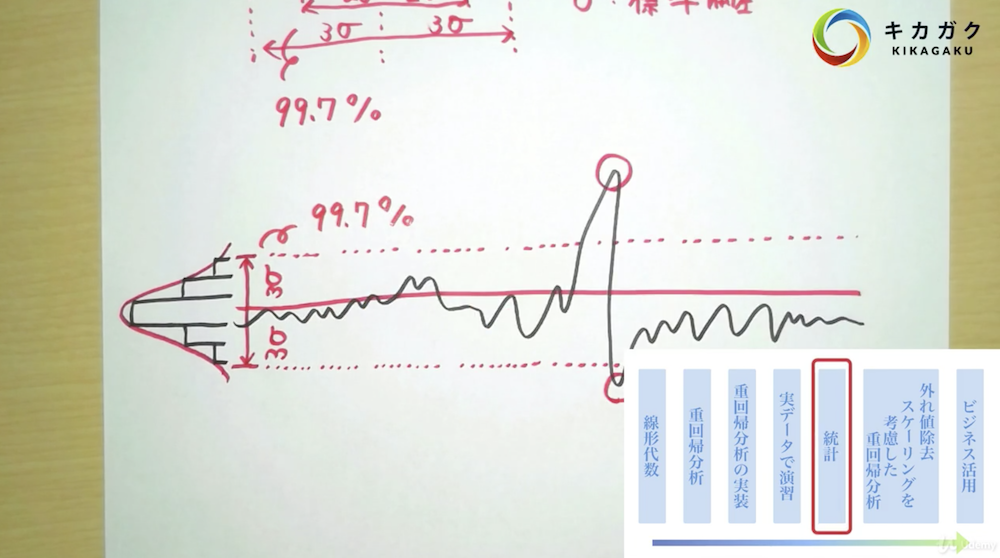
正規分布の話も。1σ、2σ、3σの話も。σ(シグマ)は標準偏差です。少し話が逸れますが、最近は仮想通貨も話題なので、チャート分析でボリンジャーバンドというものを聞いたことがある人もいるかも。それですね。株やFXなどでも出てきますよね。
-
最後のトピックはスケーリング。データの標準化について。スケールを標準化すると、どの重みが効いているかなどの議論がやりやすくなりますね。お客さんに「どうしてこんな結果になったんでしょうねえ」と聞かれても慌てなくて済みます。(他にも色々切り口はあるけれども。)
統計の解説はここまで。
JupyterNotebookに戻ります。外れ値除去、スケーリング、重回帰分析などの具体的な実装を学びます。
-
外れ値の除去は3σ法で行います。1つのパタメータにて適用する場合と、複数のパラメータに適用スうる場合の実装を学びます。
-
外れ値に対する対処法は今やった除去以外にも色々あるのでそれの紹介も。
-
外れ値を除去したことで制度が影響があったことを確認。
-
最後はスケーリング。Scikit-learnは前処理も得意です。StandardScaler()を使います。
これで中級編の内容は終了。
最後におまけの1トピックあり。現場で機械学習を導入できる人材とは?とういうテーマで講師の吉崎さんの体験を元に話をしてくれます。

このセクションの長さは14分程。この中級コースのはじめに聞いておいても良いと思います。
これで全セクションは終了。基本的に公式サイトで一覧表示されているカリキュラムに私がコメントを付けているような形になっているので、本家(公式サイト)もチェックしておいてください。カリキュラムの大枠と、その下の細かいレクチャーのタイトルが記載されています。各レクチャーの時間も記載されているため、全体のバランスもイメージできるはずです。トータルで4.5時間ほどの動画です。プレビューのリンクがあるレクチャーはサンプル視聴できるようになっています。これも要チェックです。
おわりに
というわけで、キカガクのUdemy動画(中級編)の感想を書いてみました。
今回の中級、そして前回の初級は機械学習初心者はチェックしておいて損はないと思います。苦手意識も低減されるでしょう。
この記事があなたの学習のヒントになれば嬉しいです。
キカガクのUdemy動画は以下のリンクからどうぞ。Udemyは30日間返金保証制度もあるので安心です。
▶【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 初級編 –
▶【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 中級編 –
上級編が楽しみだ!