

この記事の内容は?
PyQの新コンテンツ「機械学習/データ分析」の学習をしてみた
今回はPyQで実際に機械学習/データ分析の学習をしたレポートを紹介します。
ネットで調べて学習、書籍で学習、動画で学習、etc 色々学習する方法もあって、機械学習/データ分析は学ぶジャンルも多岐にわたるし・・・「結局何していいかわからん!」という人にはPyQのカリキュラムに沿ってひとつずつ確実にこなしていくのも良いですね。
→ オンライン学習サービスPyQ(パイキュー)の詳細はこちら
機械学習/データ分析の学習を始めたいけれど初心者だし・・・
- 機械学習って難しそう・・・
- 自分でも調べてみたけれど結局何から手を付けてよいかわからない・・・
このジャンル、学びたい気持ちがあるのに前に進めないという人は意外に多いのかも。
そんな人はPyQ(パイキュー)で手を動かしながら学んでみましょう。

PyQ(パイキュー)はひとつの解決法
というかPyQとはなんだ?
→ オンライン学習サービスPyQ(パイキュー)の詳細はこちら
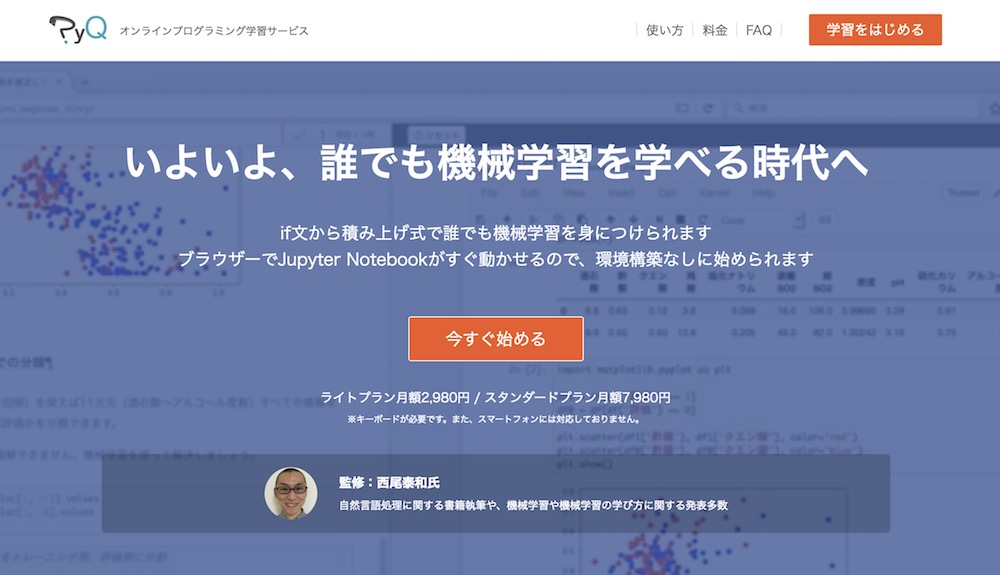
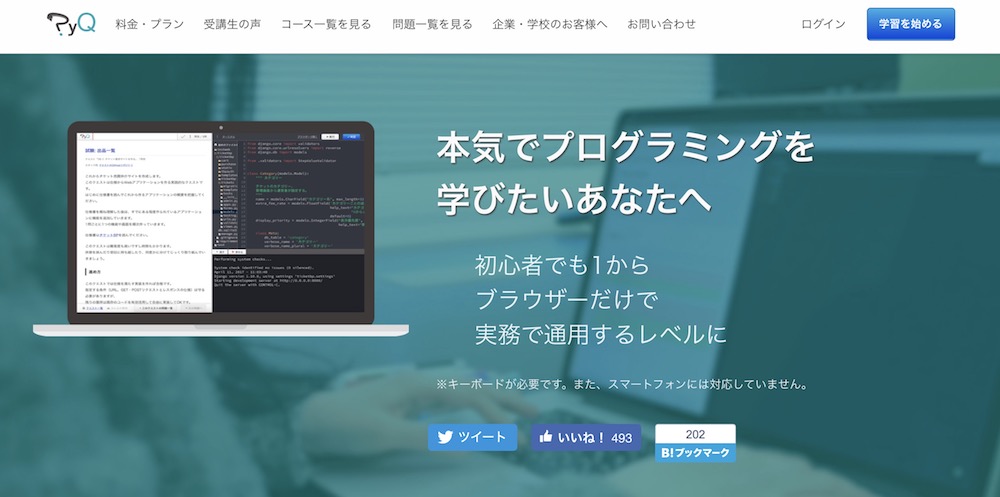
PyQ(パイキュー)はオンラインでPythonが学べる学習サービスです。
Pythonのプロフェッショナル集団が作っているだけあって、基本技術とトレンド技術のどちらも学べるカリキュラム構成になっています。また、初級レベルだけにとどまらず、中級レベルへもステップアップしていける内容なのも人気の理由でしょう。
今回は、PyQに新しく追加されたコンテンツである「機械学習/データ分析」の紹介・感想を記事にしました。
PyQの「機械学習/データ分析」はこんな人向けの学習サービス
PyQでは様々なPythonに関するテーマを扱っていますが、この「機械学習/データ分析」コンテンツは次のような方にはうってつけです。
- 本を読んだけど数式や概念が難しくてわからない…挫折してしまった
- 数学をやってないから機械学習は無理なんじゃないだろうか?
- 用語が分からず用語を調べてばかり…勉強が進まない
初心者でも学習できるように作られています。↓
プログラミング言語Pythonと業界標準のpandas、scikit-learn、JupyterNotebookを使った機械学習、データ分析の方法を学びます。
西尾泰和氏監修の下、初心者の人でも1から機械学習を学べるように作られています。
まずは動画を見てイメージするほうがわかりやすい
PyQの機械学習やデータ分析のコンテンツってどんな感じなの?そう疑問に思っている方はこの動画を見た方が理解が早いです。↓
PyQの「機械学習/データ分析」の特徴
- 初心者でも1から機械学習、データ分析を学習できる
- プログラミングの簡単な文法から積み上げ式で学習できる
- 機械学習、データ分析で 業界標準の実行環境「JupyterNotebook」に対応している
今はどこも「JupyterNotebook」を使ってますよね。ジュピターノートブックと言ったり、ジュパイターノートブックと言ったりします。(←人によって言い方が違います。汗)
PyQで機械学習/データ分析の学習をしてみたので簡単にレビュー
というわけでPyQの「機械学習/データ分析」をやってみた

→ オンライン学習サービスPyQ(パイキュー)機械学習/データ分析の詳細はこちら
以下では機械学習とデータ分析の2コンテンツに絞って感想を書いています。
カリキュラムは?
執筆時点では以下の2つから構成されています。
- Pythonデータ処理入門
- Python機械学習
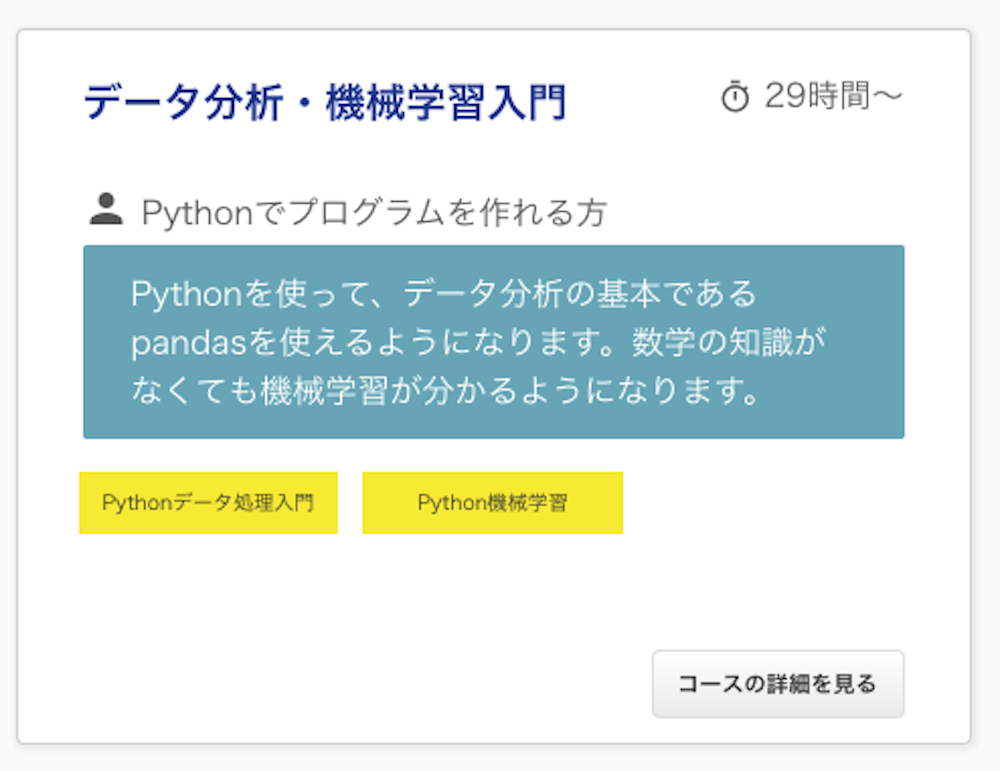
↑各クエストをピンポイントで選ぶこともできるし、上の画面のように「データ分析・機械学習入門」のコースを選ぶことも出来ます。コースを選んだほうがわかりやすいですね。
その1:Pythonデータ処理入門

Pythonでデータを扱う上で大切なライブラリのpandasについて学びます。
- Jupyter Notebookの使い方
- pandas体験
- pandasのデータ構造
- データ処理
その2:Python機械学習
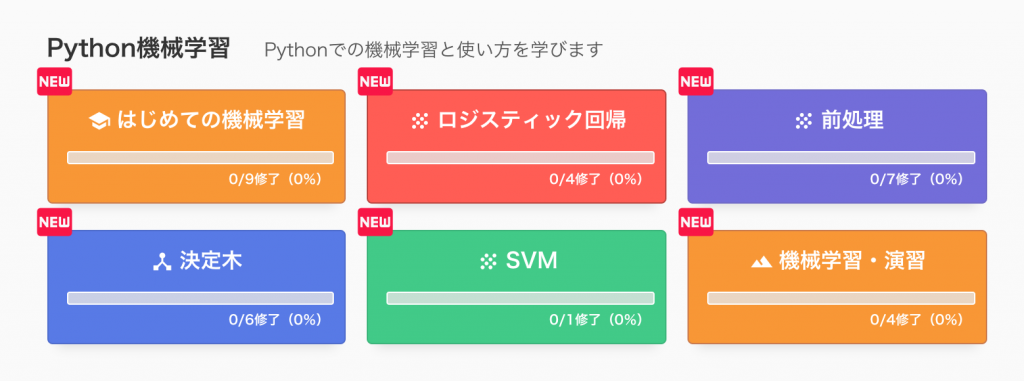
Pythonでの機械学習と使い方を学びます。
- はじめての機械学習
- ロジスティック回帰
- 前処理
- 決定木
- SVM
- 機械学習・演習
まずはその1「Pythonデータ処理入門」をやってみる
Jupyter Notebookを使うところから
データ分析系ではこのJupyter Notebookがないとはじまりませんね。
以下の内容から構成されています。
- Jupyter Notebookの基本操作
- モジュールの利用
- 関数の利用
- メニューの使い方
PyQのシステム中にJupyter Notebookが入っていました。
てっきり、Jupyter Notebookは別途インストールして使うのかと思っていたのでびっくり・・・
これならすぐに操作に移れますね。
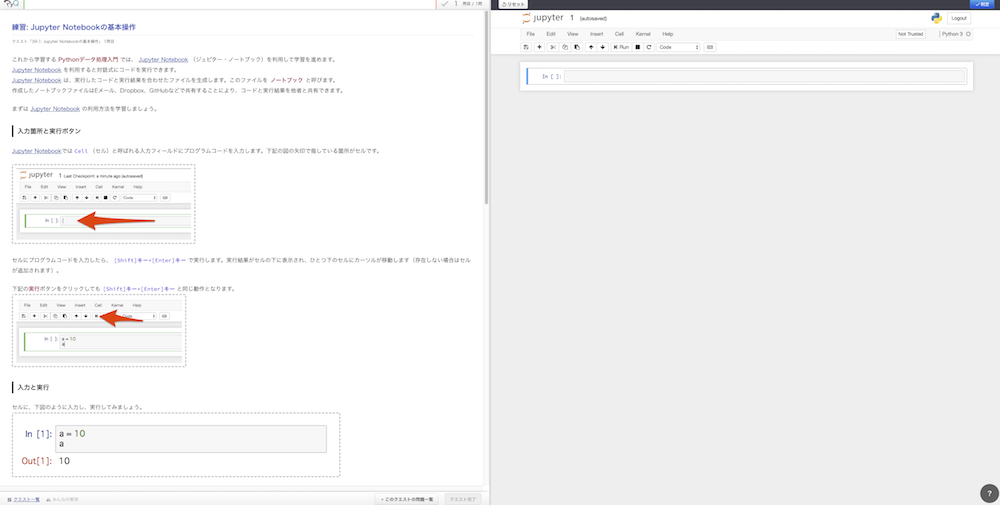
↑左が解説。右がJupyter Notebook。
基本的な入力方法、モジュールや関数の利用などを確認していきます。
またメニューの使い方についても学習します。上下ボタンでセルの移動ができるとか。
ちなみに、ちゃんと入力しないと次の問題(クエスト)には進めません。入力したら右上の「判定」ボタンを押しましょう。OKなら次に進めます。
次はpandasの学習
pandasは超重要な必須ライブラリですね。強力なPythonのデータ分析ツールとして多くの方が利用しています。というかこれを利用しないとデータ分析出来ないです。。。データの前処理には欠かせません。
学べる内容は以下のようになってます。
- はじめてのpandas
- 標準ライブラリでの集計とpandasでの集計
- 列を追加して、絞り込み
- pandasを触ってみようの確認演習
ここではpandasを扱う上で重要なデータフレームの操作を体験していきます。
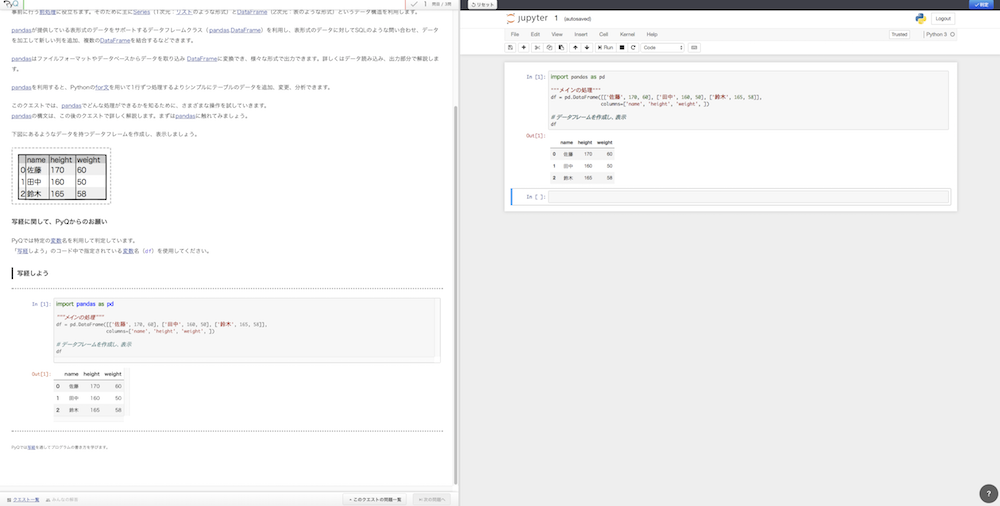
↑データフレームという概念に慣れましょう。簡単な記述で2次元の表形式のデータを操作できるようになります。便利です。
CSVファイルを読み込んだりするのも簡単にできます。CSV以外にも、Excel、テキストファイル、HTML、JSON、データベース、Google BigQueryなんかも読み込めます。関数でサクッと読み込めるのでコードをカリカリ書かずに済んでラクチンです。
例えば、CSVを読み込む場合だと、
pd.read_csv(‘xxxxxx.csv’)
これだけでOK。(簡単だ!)
また、集計などもpandasでは関数があるので数行で書けます。解説にpandasを利用しないで集計を実装する方法が紹介されていました。その場合だと10〜15行くらい書くハメになります。メンドウですね。。。
絞り込みも便利。エクセルでできることはpandasでもできますね。
pandasのデータ構造について詳しく学習
なんとなくpandasの操作もつかめてきたところで、次はpandasのデータ構造について詳しく学習していきます。SeriesとかDataFrameがメインになります。
- Seriesを学ぼう
- DataFrameを学ぼう
- DataFrameの振り返り
- DataFrameのデータ参照
- DataFrameのデータ参照振り返り
1次元データがSeries、2次元データがDataFrameですね。1次元か2次元か、それだけです。
SeriesやDataFrameに対して、具体的に操作しながら理解を深めていきます。
データを取り出した際はそのデータがSeriesなのかDataFrameなのか把握しておくことも重要ですね。わからなくなったらtype(xxxx)も使ってみるのもいいかも。
また、実データに注意がいきがちですが、ラベル(列ラベル、行ラベル)の操作もきちんと押さえておきましょう。行番号ともごっちゃにならないようにしたいです。loc()やiloc()も使いこなせるように。
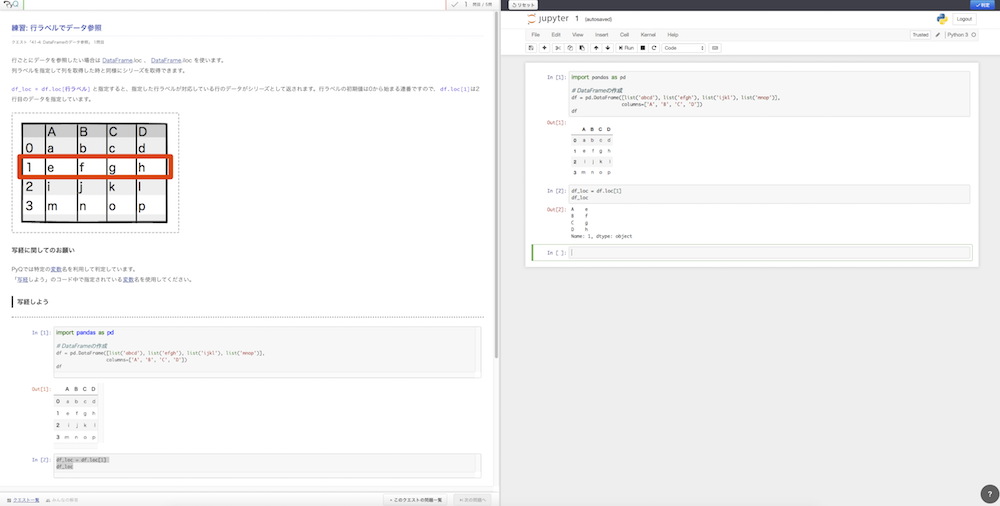
データ処理について学ぶ
pandasのデータ操作に慣れてきたところで、もう少し深い内容に突入。
- データ読み込み(read_csv)
- データ出力
- JSON形式の出力
- データの追加と演算
- データの追加と演算の振り返り
- 絞り込み
- 絞り込みの振り返り
- 関数の適用、イテレーション
- 関数の適用、イテレーション振り返り
- pandasを用いたデータ処理の確認演習
ファイルの読み込みだけではなくデータの書き込みも学習します。
すでにあるデータから新たにデータを作ったり、条件で絞り込んだり、pandasで自由に操作できるように学んでいきます。データにランクをつけたりもします。
ここで自由自在に操れるようにトレーニングしておきましょう。
以上で、pandasの学習は終了です。

↑進捗が100%になりました。
PyQではひとつひとつ確実に手を動かしながら学習を進めることができるのがGOODポイントですね。
また、例題の事例も身近な内容のため、すっと飲み込みやすくなっていると感じました。
次は機械学習の実装を行う中でpandasを利用していきます。
その2「Python機械学習」に突入
いよいよ機械学習を学びます。これまで学んだデータの操作はきっちり身に付けておきましょう。
はじめての機械学習
まずは「機械学習とは何なのか」という基本的なところが入り口です。
機械学習で実現できることって何?という根源を理解してからクエストに取り掛かりましょう。
ルールベースで良い場合、機械学習が良い場合(ルールを自動で学習)、など意識して使い分けないといけませんね。(機械学習は万能ではないので・・)
このセクションでの構成は以下のようになっています。
- 機械学習の基本をif文から学ぼう
- しきい値を見つけよう
- 可視化してしきい値を見つける
- しきい値が決められないデータの扱い方
- 2次元のデータから分類
- 2次元データをプロット
- 1次方程式を用いた分類
- はじめての機械学習:ロジスティック回帰
機械学習を始める前に、まずは数値をながめて分類条件を検討したり、グラフにプロットしてデータの傾向や特徴を探るところからはじまります。
その2「Python機械学習」はその1「Pythonデータ処理入門」に比べて、一つ一つのクエストがちょっとだけボリュームがある傾向。(そんなにがっつりではないです。)
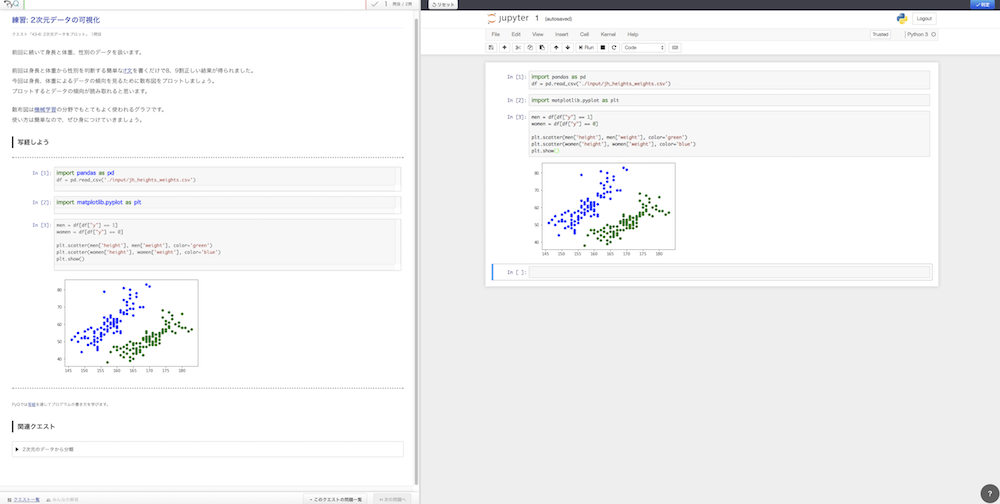
↑ matplotlibでグラフが簡単に書けます。2次元データを可視化しています。グラフにするのは楽しいですよね。
最後はついに機械学習。ロジスティック回帰を学びます。ロジスティック回帰はデータを線形に分類することができる手法です。ここでライブラリのscikit-learnが登場。
scikit-learnから機械学習のモデルを読み込み、学習させ、予想させます。
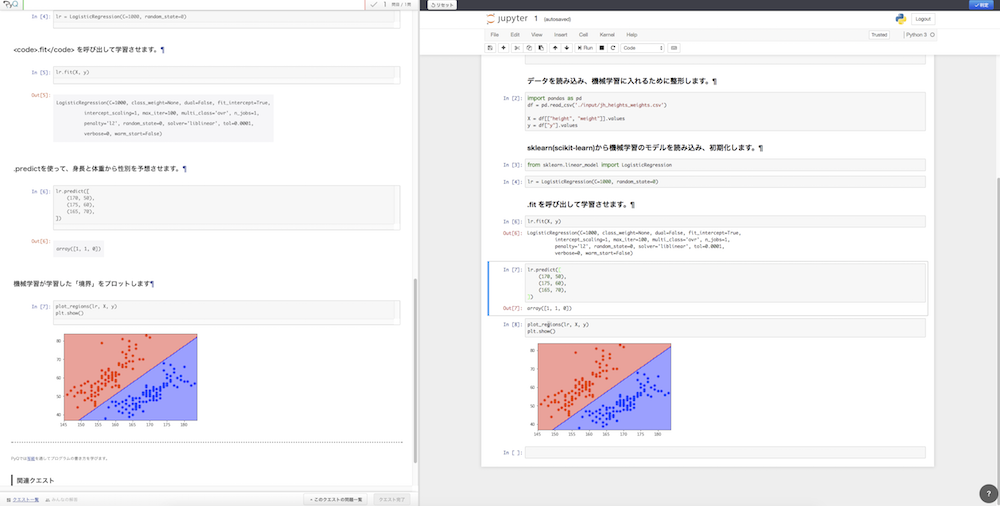
↑機械学習が学習した「境界」をプロットします。きれいに境界を分けることが出来ました。
ロジスティック回帰
次はロジスティック回帰を深く学んでいきます。
- ワインの評価を推定してみよう
- ロジスティック回帰の弱点
- 特徴を加えて線形分離可能にする
11次元のワインのデータから評判の良いワインかどうかを判定したり…と、より具体的な内容になっています。
また、ロジスティック回帰に不向きなデータのパターンも学べます。万能ではないですから。
不向きなデータに対して一工夫を加えることでロジスティック回帰で分離する方法も学べたり。
前処理
「データ分析は前処理がほとんど」言う人もいるくらい重要なところです。
データセットに含まれる欠測値を除去・補完する方法をひとつずつ試します。
- 欠測値に対処しよう
- カテゴリデータを処理しよう
文字列で分類されているデータを数値に変換して機械学習にかけて、そして最終的に再度文字列に戻す、という操作ははよく使いそう。ベタで書いても実現できるけれど、scikit-learnなどを利用するともう少し簡単に出来ますね。コードが簡潔になります。
one-hotエンコーディングも重要な考え方です。押さえておきましょう。
決定木
次は決定木の学習。線形非分離なデータを決定木を使って分類する方法を学習します。決定木はなんぞや?というところからはじまります。
構成は以下のようになります。
- 決定木を使って分類しよう
- 過学習の罠
- ハイパーパラメータのチューニング
- アンサンブルとランダムフォレスト
過学習によって正解率が落ちることも理解しておきましょう。と同時に学習時の過度な最適化を制限するためのハイパーパラメータについても押さえておきましょう。クロスバリデーション(交差検証法)も重要な考え方です。
決定木を組み合わせたランダムフォレストについても学びます。
そしてSVM(サポートベクターマシン)
非線形分離可能なSVMを学びます。曲線で分離します。SVMにカーネル化という手法を組み合わせた「カーネルSVM」を使うことで非線形分離問題にも対応できます。scikit-learnを使えば簡単に使えますね。
ここでは1つだけのクエストになります。
- SVMを使ってみよう
曲線で分離できるというのも面白いですね。結果をグラフにして可視化したときは感動があります。
最後は「機械学習・演習」
いよいよ最後です。やっとここまで来ました。
テーマは、
機械学習の演習を通して実際にどんな場で機械学習が活用できるかを身につけます。
となります。
構成については以下のように実例に基づいて学習できるようになっています。
- 機械学習でマーケティングをしてみよう
- 文章のポジティブ、ネガティブ判定
- 手書き文字の画像を認識しよう
- 年収の判定
これまでに学習したロジスティック回帰、ランダムフォレスト、SVMなどを使って正解率の高い予測を目指しましょう。
機械学習をつかったマーケティング(銀行の例)、商品のレビュー文章のポジティブ/ネガティブ判定、手書き画像(数字)を使った文字判定、人の年齢や職種からの年収判定、を演習していきます。
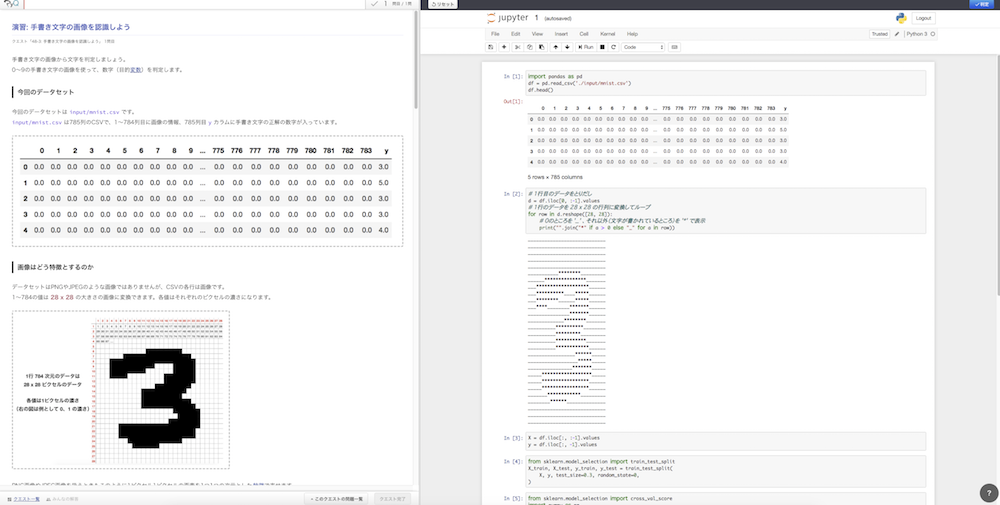
↑手書き文字の画像を使った演習の例。
という感じで機械学習のカリキュラムも終了です。
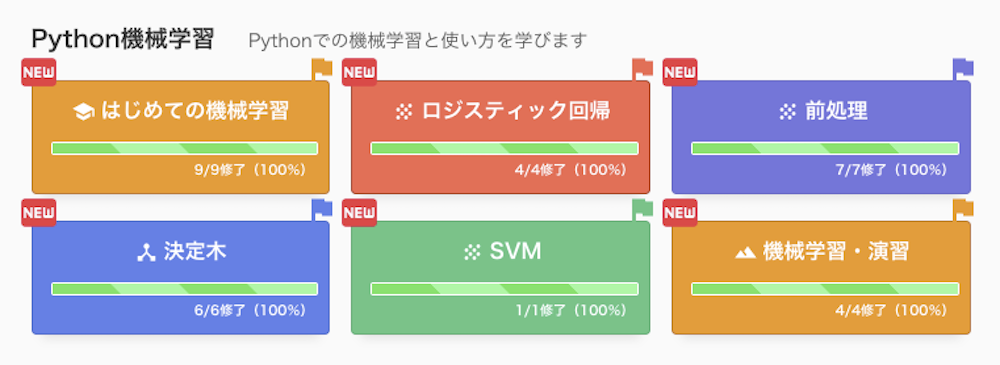
↑進捗が100%になりました。
以上で、「機械学習/データ分析」の学習は終了
すべて終えると以下のような表示になります。
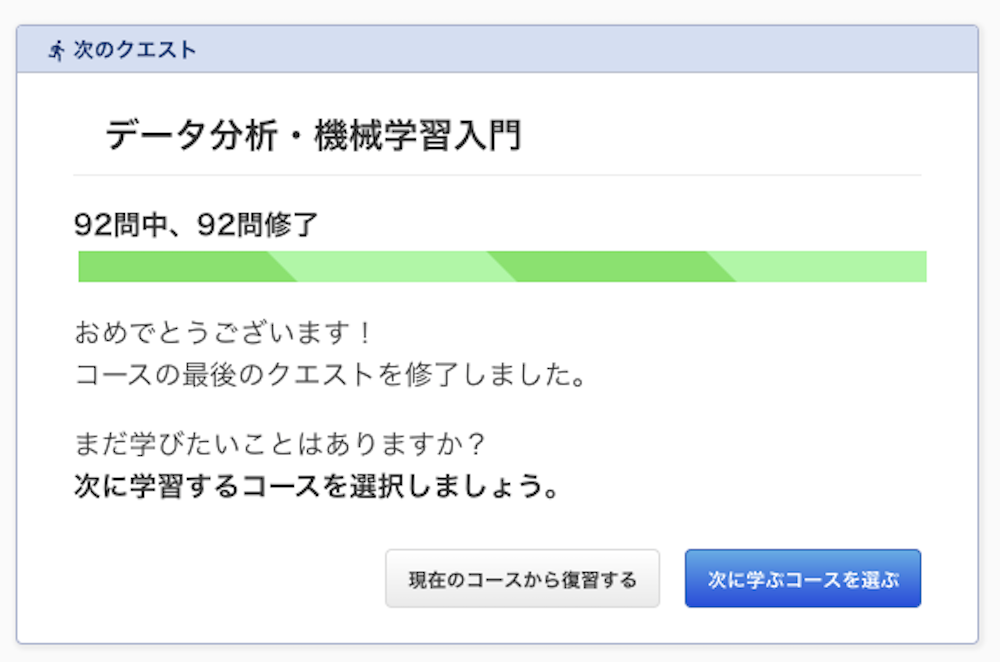
おめでとうございます!
コースの最後のクエストを修了しました。まだ学びたいことはありますか?
次に学習するコースを選択しましょう。
↑クエストをすべてクリアして100%になりました。気持ち良いですね!
PyQのカリキュラムに身を任せるのもいいかも
PyQでは実際に手を動かしてクエストを進んでいきます。この「機械学習/データ分析」も最初から最後までやりきれば力はつくでしょう。
カリキュラムが良かったです。それぞれのクエストのボリュームがちょうどよいです。クエストは全部で92。(←執筆時点です。)なかなかやりごたえがあります。
ここで付けた知識を元に、次のステップに進んでいきましょう。ベースの力はついたはずです。次は新たなアルゴリズムの学習に進むも良し、身近な問題をどんどん機械学習してみるも良しです。ディープラーニングの学習に進んでみるのも面白いかも。
PyQ利用者の体験談も紹介
PyQ利用者の公式サイトにはたくさんの体験談があるので時間がある方は確認してみてください。以下では少しだけ紹介。
PyQではエディタと実行環境がwebアプリケーション内で用意されており、コードが仕様通りに動作しているかも判定してくれるため、プログラミングを学ぶ上での障壁がとても低くどんどん前に進むことができました。
PyQではクエストを解いていくにつれてわからなかった問題もちゃんと理解できるようになっていくのが実感できます。プログラムと聞いて難しそうと思った方や他のプログラムを学んで挫折した方におすすめしたいです。
「もう少しここを知りたいのにどうやって学べばいいかわからない!」「せっかく学ぶのだから中途半端でなくガッツリ学びたい!」という人は挑戦してみる価値があると思いますよ。
受講してみて、プログラミング初心者にとってもわかりやすい構成となっており、効率よく短期間でスキルを身につけることのできるサービスだと感じました。
PyQは月額制だけれど日割り計算なので安心・良心的
途中でやめたとしても、日割り返金してくれるサービスって最近はあまり見かけなくなったような・・・
PyQでは日割り計算で月額料金を返金してくれます。(←本記事執筆時点。)
PyQは解約のタイミングで日割の料金で返金されます。 お好きなタイミングでコース変更いただけます。
これはとても良心的だと思います。なのでとりあえず初めてみて、違ったと思ったらやめるという使い方も出来ます。
通常利用のライトプランは月額2980円(税込)です。わからないところをメールで質問してサポートしてもらえるスタンダードプランは月額7980円です。私はなんとなくライトプランが多いのかなと思ってましたが、意外にサポート付きのスタンダードプランも多いようです。(←そりゃそうか。Pythonのプロフェッショナル集団からサポートしてもらえるのだから。)
これからPythonをがんばりたいならPyQはチェックしておこう
いかがでしたでしょうか。
今回紹介したPyQの「機械学習/データ分析コース」は機械学習やデータ分析を頑張りたい方、そしてPythonの知識の全体像を把握したい方にはオススメです。集中すればサクサク進むはずです。完走すると全体感がつかめます。
PyQではじっくり1つずつ確認しながら学習を進めることができます。手を動かしながら確実に学んでいきたい方にはPyQは良い学習の選択肢になるはずです。
気になる方は以下のPyQ公式サイトを確認してみてくださいね。「百聞は一見に如かず」です。↓↓
→ オンライン学習サービスPyQ(パイキュー)の詳細はこちら
→ オンライン学習サービスPyQ(パイキュー)機械学習/データ分析の詳細はこちら
それでは〜